Perustiedot AMD:n Bulldozer- ja Bobcat-arkkitehtuureista
Artikkelin kirjoittaja: Manu Pitkänen | 0 kommenttia
Lisää Bulldozerista
Todellisuudessa valtaosa kaikesta siitä mistä AMD puhui Hot Chips –tilaisuudessa oli jo entuudestaan tiedossa.
AMD käytti paljon voimavaroja Bulldozeriin ja sen tapaan käsitellä säikeitä. AMD on tehnyt selvän pesäeron perinteisen yhtäaikaisen monisäikeisen laskennan (joka juontaa juurensa Intelin Hyper-Threadingiin) ja sirutason moniprosessoinnin, jossa jokainen ydin vastaa omasta säikeestä, välille.
Moniprosessoinnissa (CMP) siis periaatteessa fysikaalisia ytimiä monistetaan ja säikeistetyt ohjelmien suorituskyky skaalautuu ytimien määrän mukaisesti, siis periaatteessa. Brute-force-tuottaa parhaimman hyödyn, mutta on samalla liian kalliiksi jos voimavaroja jätetään käyttämättä. Siksi suosittelemme mieluummin nopeaa neliydinprosessoria hitaamman kuusiytimisen sijaan pelaamiseen. Ellei työtaakka ole oikealla tavalla optimoitu rinnakkaislaskentaan, niin CMP on kuin ampuisi pyssyllä hyttystä.
Intel on kehittänyt korvaavan teknologian CMP:lle, jota se kutsuu Hyper-Threadingiksi. Se mahdollistaa neljän säikeen suorittamisen kahdella ytimellä. Teknologia on suhteellisen edullinen toteuttaa, mutta kaikki ohjelmat eivät pysty hyödyntämään siinä olevaa potentiaalia. Toiset ohjelmat eivät nopeudu kuin hädin tuskin 10 prosenttia.

AMD on tuo uusissa arkkitehtuureissaan kolmannen tavan rinnakkaislaskentaan, yhti kutsuu sitä nimellä Two Strong Threads. Siinä missä Hyper-Threadingissa kaksinkertaistetaan arkkitehtuuriset tasot, niin Bulldozerissa käytetyssä ratkaisussa ytimien etuosat (haku/dekoodaus) ja takaosat ovat sulautettu yhteen (jaetun L2-välimuistin kautta). Samalla prosessorin kokonaislukuajastimien ja liukuhihnojen lukumäärä on kaksinkertainen, joten jokainen säie käsitellään fyysisesti erillään.
Säiepari jakaa saman liukulukuajastimen, johon yhdistetty kaksi 128-bittistä fused multiply-accumulate-capable units. Samalla voidaan havaita, että AMD panostaa selvästi kokonaislukulaskentaan. Pidä mielessä, etteivät ensimmäiset Bulldozer-prosessorit ole APU-prosessoreita. Vaikka AMD onkin päätynyt jakamaan liukulukulaskennan voimavarat GPU:n ja x86-ytimien kesken, niin AMD haluaa pitää tasapainon jaettujen komponenttien ja tietylle komponentille omistettujen komponenttien välillä.
Mikään edellä kuvattu asia ei ole uutta, yhtiö puhui näistä asioista jo viime marraskuussa.
Ennen Hot Chips –esitelmää me saimme mahdollisuuden keskustella AMD:n teknisestä suunnittelun varajohtaja Dina McKinneyn kanssa ja päivittää hieman tietojamme Bulldozeriin liittyen. McKinneyn mukaan yhtiön valitsema Two Strong Thread –lähestymistapa tuottaa 80 prosenttia siitä suorituskyvystä kuin saataisiin monistamalla ytimien määrää. Samalla joidenkin osien jakaminen komponenttien kesken mahdollistaa pienemmän tehonkulutuksen.
Tämän ominaisuuden ja 32 nanometrin SOI-tekniikan käyttöönoton myötä AMD:n ytimien määrän nähdään kasvavan 33 prosentilla, mutta suorituskyky kasvaa 50 prosentilla, kun vertailukohtana on Magny-Course-pohjaiset prosessorit ja lämmöntuotto molemmissa tapauksissa pidetään samana. Vertailussa on siis käytetty nyt myynnissä olevia 12-ytimisiä 6100-sarjan Opetron-prosessoreja ja tulevia 16-ytimisiä Bulldozer-arkkitehtuuriin perustuvia Interlagos-prosessoreja.
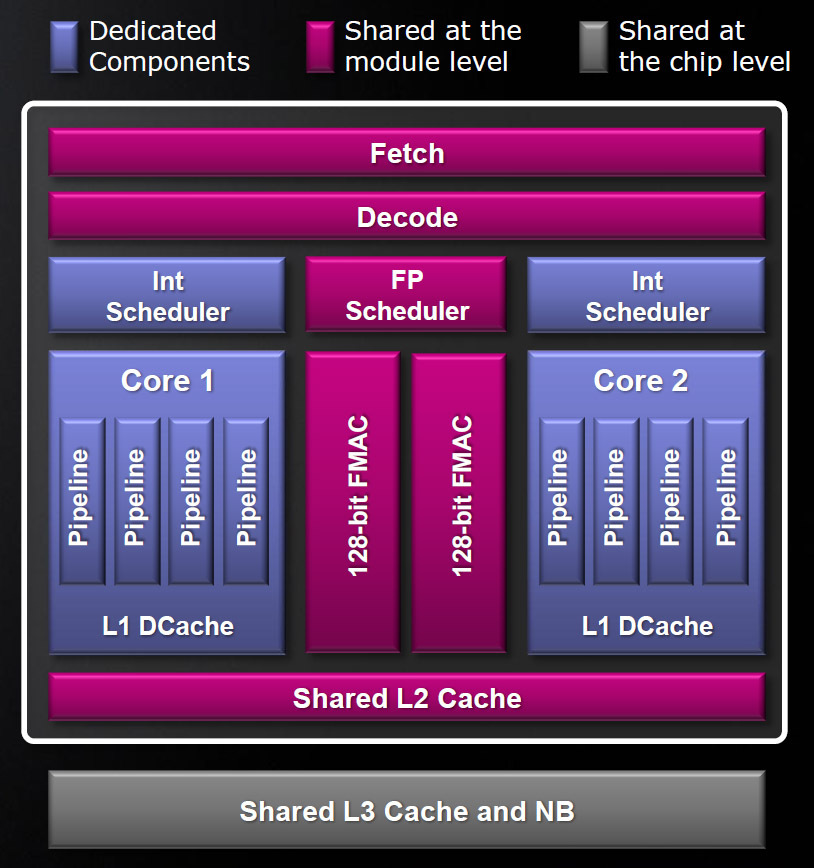
Kerroin AMD:lle, että heidän Bulldozer-moduulinsa näyttää pahasti SMT-tuelliselta yksiytimiseltä prosessorilta. AMD ei ole halunnut kaksinkertaistaa rekistereiden määrää, joten AMD antaa jokaiselle säikeelle oman käskyikkunan ja omat liukuhihnat. AMD:n John Fruehen kanssa käydyn keskustelun jälkeen minulle selvisi, että yhtiö pitää moduuliaan enemmän kaksiytimisenä, kuin SMT:nä – kokonaislukuajastimien ja niiden liukuhihnojen lukumäärän vuoksi. Tämä menee mielestäni liian paljon kauppapuheiden puolelle, mutta olen kaikesta huolimatta iloinen päässäni näkemään arkkitehtuuria joka pärjää Hyper-Threadingia paremmin rinnakkaislaskennassa.
On mielenkiinoista nähdä miten Bulldozerin moduulit suhtautuvat Windows 7 –käyttöjärjestelmän kanssa. Intel ja Microsoft ovat yhdessä optimoineet Hyper-Threading-ominaisuutta. Windows-käyttöjärjestelmä osaa erottaa fyysisen ytimen ja Hyper-Threading-ytimen toisistaan. Windows 7 ja Server 2008 R2 –käyttöjärjestelmät suorittavat oletusarvoisesti kahden säikeen prosessin kahdella fyysisellä ytimellä, koska säikeiden jakaminen fyysiselle ytimelle ja HT-ytimelle olisi hyötysuhteen kannalta liian huono tapa. Tämän perusteella sanoisin, että neljästä moduulista koostuva Zambezi-prosessori suoriutuisi parhaiten laskemalla säikeet eri moduuleissa. AMD ei kuitenkaan osannut vastata vielä miten asia tullaan toteuttamaan. AMD kuitenkin vakuutti, että he ovat yhteistyössä käyttöjärjestelmävalmistajien kanssa, ja käyttöjärjestelmät pitäisi saada optimoitua ajoissa ennen Bulldozerin julkaisua.
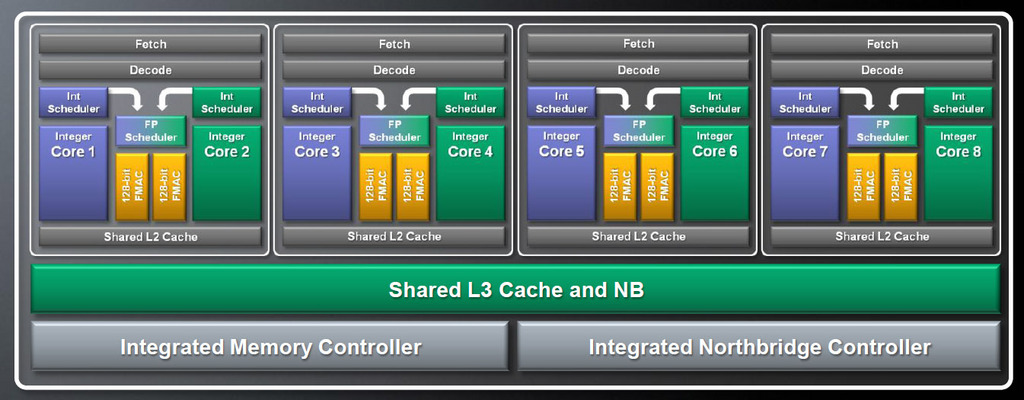
Kysyin Fruehelta myös etuosan käskykantaominaisuuksista ja jaetusta L2-muistista, mutta tietoja näistä ei haluttu tarkentaa vielä. Hän pystyi kuitenkin kertomaan, että 128-bittiset liukulukuyksiköt ovat symmetriset, ja että minkä tahansa syklin aikana kumpi kokonaislukuydin voi suorittaa 256-bittisen AVX-käskyn (mikäli ohjelma tukee AVX-käskykantaa). On myös mahdollista, että ytimet suorittavat kaksi 128-bittistä käskyä samanaikaisesti.
Fruehe selvensi myös kokonaislukuyksikköjen liukuhihnojen suuntautuneisuutta. K10-arkkitehtuurissa oli kolme liukuhihnaa jaettuna ALU-yksikköjen ja AGU-yksikköjen välille (efektiivisesti siis 1,5). Bulldozer-arkkitehtuurissa liukuhihnoja on neljä, kaksi ALU-yksiköille ja kaksi AGU-yksiköille. L1-välimuistiin on myös tullut muutoksia. Aiemmin K10-arkkitehtuurissa oli 64 kilotavun L1-käskymuisti sekä 64 kilotavun L1-datamuisti jokaista ydintä kohden. Bulldozerissa on päädytty 16 kilotavun datamuistiin ydintä kohden ja 62 kilotavun kaksisuuntaiseen käskymuistiin moduulia kohden.
Kommentoi artikkelia
Kirjaudu sisään