AMD Radeon HD 7970: matka Tahitiin
Artikkelin kirjoittaja: Panu Roivas | 0 kommenttia
Graphics Core Next: Southern Islands -arkkitehtuuri
Radeon HD 7970 on ensimmäinen AMD:n GCN-arkkitehtuuria hyödyntävä näytönohjain, mutta arkkitehtuuri ei itsessään ole ollut mikään salaisuus. Antaakseen tarpeeksi akaa kehittäjille hyödyntää tulevaa arkkitehtuuria, Graphics Core Next julkistettiin heinäkuussa 2011 Fusion Developer Summit -tapahtumassa. AMD:n CTO Eric Demersin mukaan vanhassa VLIW-arkkitehtuurissa oli vielä lisää grafiikkapotentiaalia, mutta se oli rajoittuneempi yleislaskennassa. Vanhan kierrättämisen sijaan yritys päätti panostaa kokonaan uuteen arkkitehtuuriin.
Laskentatehon kasvattaminen ja GPU:n ohjelmoitavuuden lisääminen ovat hienoja asioita, mutta pelisuorituskyky ja kuvanlaatu ovat edelleen se tärkein seikka näytönohjaimissa. AMD:n haasteena oli siis luoda GPU parantaen kaikkia osa-alueita. Tätä varten yritys heitti hyvästit Very Long Instruction Word -arkkitehtuurille, ja kehitti tilalle Graphics Core Nextin.
Graphics Core Next ja hyötysuhde
AMD:n VLIW-arkkitehtuuri on hyvin tehokas grafiikan laskemisessa. Sen kääntäjä on optimoitu laskemaan 3D-grafiikkaan liittyvää matematiikkaa. Sen heikkous ilmenee kun sen on skeduloitava GPGPU-skalaarikäskyjä. Kääntäjän on tehtävä paljon töitä maksimoidakseen optimoinnin, ja sen on tehtävä jonkin verran arvauksia. Välillä tielle ilmestyy käskysarjoja joita ei voi suorittaa ennen kuin aikaisempi käskysarja on valmis. Toisin sanoen ne ovat riippuvaisia toisistaan (dependency). Kääntäjä ei pysty muuttamaan käskysarjajonoa kun se on jo skeduloitu, eli jos käskyjä joudutaan odottelemaan riippuvaisuuden takia, ALU-suorituskykyä menee paljon hukkaan.
Alla on teoreettinen esimerkki siitä, kuinka Radeon HD 6970:n VLIW4 SIMD-moottori ja sen 16 riviä varjostinyksiköitä (jokaisessa SP:ssä neljä ALUa, eli yhteensä 64 ALU-yksikköä per SIMD-moottori) hoitavat käskysarjajonon, jossa on riippuvaisuussuhteita.


VLIW-arkkitehtuuri ei siis hoida riippuvaisuussuhteita ideaalisesti. Käskysarjat joutuvat odottamaan tarpeettomasti jonossa vapaiden ALU-yksiköiden ollessa tyhjän panttiana. Kuinka siis optimoida tehty skalaarityö per kellosykli? Vastaus on Compute Unit, eli laskentayksikkö. CU:lla on oma vuorotin (scheduler), joka pystyy asettamaan käskysarjoja vapaille vektoriyksiköille rajoitetusti out-of-order -tyyliin välttääkseen turhaa odottelua.
Compute Unit korvaa vanhan SIMD-moottorin, johon olemme jo tottuneet. Jokaisella CU:lla on neljä vektoriyksikköä (VU), joissa on jokaisessa 16 ALUa, eli yhteensä 64 ALUa per CU. Näin ollen ALU-yksiköiden määrä per SIMD/CU pysyy samana. Suurin ero on siinä, että toisin kuin SIMD-moottorin varjostinyksiköt, jokainen vektoriyksikkö voidaan vuorottaa erikseen.
Tämä on avain parempaan GPGPU-laskentaan, sillä se mahdollistaa VU:n tehdä töitä eri käskysarjoilla vaikka niillä olisi rippuvaisuussuhteita jonossa:
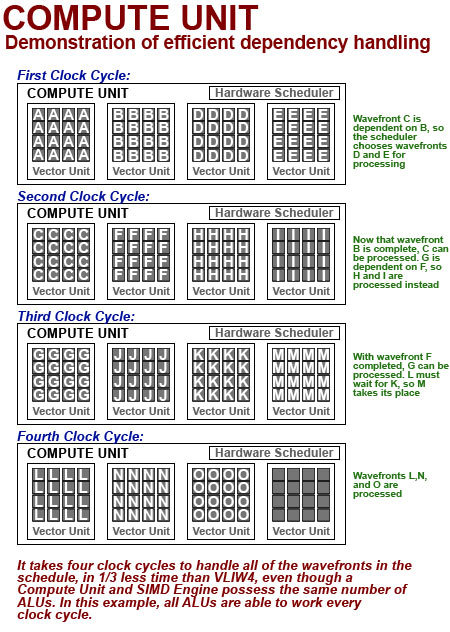
Esimerkissämme sama käskysarjajono, joka kesti kuusi kellosykliä VLIW4 SIMD -moottorilla, voidaan ajaa neljässä kellosyklissä GCN:llä. Tämä on perimmäisin syy uuden arkkitehtuurin parempaan hyötysuhteeseen VLIW-arkkitehtuuriin nähden, ja AMD:n omien laskelmien mukaan Radeon HD 7970 tarjoaa jopa 7,5x paremman teoreettisen laskentatehon parannuksen Radeon HD 6970:n verrattuna. Käytännön suorituskykyero riippuu kääntäjän tehokkuudesta, ja joissain laskentatöissä Radeon HD 7970 on vain vain hädin tuskin parempi kuin 6970 per-ALU ja per-kellosykli. Näimme paljon vaihtelua omissa testeissämme, kuten tulet näkemään. Voimme kuitenkin huoletta todeta, että synteettisten testien perusteella Graphics Core Nextin laskentapotentiaali on selvästi parempi kuin VLIW4:n.
Syvemmälle laskentayksikköön

Kuten aiemmin kerroin, CU korvaa SIMD-moottorin, joita olemme nähneet Radeon HD 2000 -sarjasta lähtien. CU koostuu neljästä vektoriyksiköstä, joissa on 16 ALUa sekä rekisteri. Tiedämme myös jo, että vektoriyksiköt voivat toimia toisistaan riippumatta.
Syvenytään hieman vektoriyksiköihin. Toisin kuin yksinkertaistetussa esimerkissämme, jokainen vektoriyksikkö pystyy prosessoimaan neljänneksen yhdestä käskysarjasta per sykli. Neljällä VU:lla varustettuna yksi CU pystyy jatkuvasti prosessoimaan neljää käskysarjaa joka neljäs sykli, eli yksi käskysarja per sykli per CU. Vektoriyksiköt voidaan ohjelmoida skalaarisesti, ja jokainen toimii vektoritilassa.
Emme ole vielä puhuneet CU:n skalaariyksiköstä, joka on vastuussa haarautumisesta ja osoitinaritmetiikasta. Vektoriyksiköt pystyvät hoitamaan myös näitä käskyjä, mutta tämän apuprosessorin tarkoitus on auttaa skalaarilaskennassa antamalla vektoriyksiköiden käyttää aikansa tehokkaammin.
Jokaisella CU:lla on neljä tekstuuriyksikköä 16 KB read/write L1 -välimuistilla, mikä on kaksi kertaa enemmän kuin VLIW4:n read-only -välimuisti. Perinteisesti L1-välimuistia käytettiin vain lukemaan tekstuureja. Nyt välimuistia voidaan edetä molempiin suuntiin.
Kommentoi artikkelia
Kirjaudu sisään